Säkerhetsverktyget Bloodhound finns nu ute i en ny utgåva vid namn BloodHound Community Edition (CE). BloodHound skapades 2016 av Rohan Vazarkar, Will Schroeder och Andy Robbins. Den har laddats ner närmare 500 000 gånger och har över 12 000 användare i BloodHound Community Slack. BloodHound har rekommenderats av US Cybersecurity, Infrastructure Security Agency (CISA) och av Microsoft för att hjälpa till att säkra Microsoft Active Directory och Azure AD.
BloodHound CE är den nya och fria, öppna versionen av BloodHound och som alltid kommer alltid att vara gratis under en Apache 2.0-licens. Den delar nu kodbas och dokumentation med BloodHound Enterprise (BHE), vilket innebär konsekventa och högkvalitativa uppdateringar. Från bl.a. SpecterOps som står bakom utvecklingen till stor del.
Nya funktioner och förbättringar
Ny arkitektur: BloodHound CE har en arkitektur med flera front-end och back-end komponenter, inklusive Postgres och Neo4J databaser, ett nytt REST API och en helt ny frontend-webbapplikation
Förenklad implementering: Alla komponenter presenteras nu i en helt containeriserad modell, vilket gör det enklare att köra BloodHound CE (se nedan)
Nytt GUI: Det nya gränssnittet är helt ombyggt och använder design och komponenter från BloodHound Enterprise, med diverse förbättringar
Säkerhet och autentisering: Nya funktioner inkluderar Cypher-inmatning, cachade frågeresultat och möjligheten att hantera användare och autentisering
Introduktion av BloodHound API
BloodHound API är en autentiserad REST API som accepterar och returnerar JSON-formaterad data. Det öppnar spännande möjligheter för att fråga BloodHound och få tillförlitlig, välformaterad data som kan användas som indata för andra verktyg.
Vad är nästa steg?
Denna första release av BloodHound CE är ett tidigt tillgänglighetsbygge. Applikationen är fullt funktionell och stabil, men det finns några kända buggar som arbetas med. Feedback är mycket välkommen, och du kan gå med i BloodHound Slack eller rapportera problem på BloodHound GitHub-repo.
Denna release markerar en helt ny era för BloodHound CE, med en helt ombyggd applikation som delar en gemensam kodbas med BHE. Detta innebär snabbare och enklare uppdateringar och community-bidrag i framtiden.
Ladda hem och testa nya BloodHound CE
Teamet tillhandahåller en docker-compose YAML-fil som enkelt kan laddas hem och startas. Ungefär något liknande bör fungera väl:
$ mkdir bloodhound-ce && cd bloodhound-ce
$ wget https://raw.githubusercontent.com/SpecterOps/BloodHound/main/examples/docker-compose/docker-compose.yml
$ docker compose up
Sen väntar du ett stund och läser texten som visas på skärmen när du kör docker compose up, där står lite intressant information som är viktig att ta del av. Bl.a. så står lösenordet till webbgränssnittet som du kan behöva. Exempelvis:
Du loggar sedan in mot localhost:8080 med din webbläsare och användarnamnet admin med lösenordet som visades upp.
Om du inte har en demo-miljö eller liknande och vill testa lite så finns det ett github-repo med test-data som du kan importera till Bloodhound (kolla även BadBlood):
Viktigt att poängtera är att det inte finns något enkelt sätt i GUI:t att ladda upp JSON/ZIP-filer, som det fanns i tidigare versioner av Bloodhound. Det sättet jag gjorde var att använda python-programmet bloodhound import från Fox IT, installeras genom följande kommando:
pip install bloodhound_import
Sedan kan man köra:
for a in *.json; do bloodhound-import -p 7687 -dp bloodhoundcommunityedition -du neo4j $a; done
Observera att detta kräver att du exponerar port 7687 från Neo4j-containern. Det gör du enklast genom att modifiera docker-compose.yml. Viktigt att poängtera att lösenordet ovan som är bloodhoundcommunityedition bör ändras.
Nu bör demo-datat vara importerat och du kan använda API:et eller webb GUI:t. För mer information om REST API:et se apiclient.py samt följande supportsida hur du skapar upp API-nycklar.
Hur du enklast identifierar brister och tar över ett Windows AD är utanför denna guide.
Denna vecka befinner jag mig i London på cybersäkerhetskonferensen Blackhat. Konferensen går i USA, Asien samt Europa årligen. Tidigare har konferensen varit i Amsterdam, Barcelona och denna gång var det Londons tur. Priset för konferensen ligger på runt 1000€ och den som vill kan även gå utbildning två dagar innan konferensen (briefings) börjar.
På konferensen finns det fyra olika spår med olika inriktning. Jag har blandat mellan dessa olika spår och skrivit sammanfattningar nedan från den första dagen. Presentationen som PDF finnes även efter varje sammanfattning.
Föreläsare: Elvis Hovor och Mohamed El-Sharkawi från Accenture
Förr eller senare blir alla organisationer drabbade av intrång, och det första vi gör är att använda våra verktyg och metoder för att undersöka intrånget. Även så kräver undersökningar efter ett intrång mycket resurser framförallt i form av tid.
Föredraget och forskningen bakom handlar om att förkorta tiden att från ett larm eller befarat intrång till att det går att bekräfta intrånget. Det kan röra sig om veckor eller månader i dagsläget. Frågor som incidentutredningen måste besvara är såsom vem låg bakom, vilken information har vi blivit av med, hur tog dom sig in, varför gjorde de intrånget.
Målet är att på ett formaliserat och återupprepat sätt fokusera på:
Snabbare utredningar
Enklare utredningar
Ta bort tråkiga och autonoma delar
En oerfaren forensiker kan göra avancerade utredningar
Minska risken inom organisationen genom att förkorta tiden
Hur kan vi analysera manuella moment och kompetenser hos en individ som genomför en forensisk utredning och automatisera detta och bygga ett verktyg för att göra detta.
Fyra huvudkategorier som forskningen fokuserar på:
Omfattande cyberontolog: Unified Cyber Ontology (UCO), ICAS och CMU Insider Threat Ontology
System som kan dela information och prata med varandra: STIX CybOX CVE
Maskininlärning och kognitivitet: DFAX, CRE
Globalt incidenthanteringskorpus
Kognitiva modeller som använder Binary Tree Traversal med en egenutvecklad poängtabell. Genom att analysera flertalet olika vägar i trädet som ger olika poäng så kan bästa metoden att genomföra en incidentutredning identifieras, “workflow paths”.
Efter ett tag kunde forskarna förbättra utredningarna och även förbättra den kognitiva modellen med en Markov-kedja. Bygga incidenthanteringsrobotar med hjälp av SPARQL.
Förläsare: Mateusz Jurczyk från Google Project Zero
Att fuzza handlar om kort och gott om att automatiskt generera mängder med indata till mjukvara och förstå hur mjukvaran hantera dessa olika inputs. Arbetet börjar med att identifiera olika typer av indata exempelvis i form av olika filformat. Dessa filformat kan sedan innehålla mycket komplexa strukturer. Att crawla internet efter exempelfiler är också en metod att hitta nya testfiler.
Genom att analysera mjukvaran som ska fuzzas och hur denna laddar in filer så är det även möjligt att se vilka filformat som supportas. Detta är viktigt för att försöka ladda in så många olika filtyper som möjligt och fuzza dessa. Det är även bra om så få ändringar som möjligt nå så många funktioner inom programmet som möjligt “byte to function ratio”.
Att se code coverage genom att räkna hur många basic blocks som träffas är en grov men ändå bra metod att se hur mycket av koden som träffas i fuzzningen. Dock kan vissa vägar inom samma block missas om det finns if-sats eller liknande. AFL av lcamtuf har tänkt på vissa av dessa problem i AFL technical whitepaper.
SanitizerCoverage är ett verktyg som lätt och enkelt kan mäta code-coveredge.
Nytt förslag från Mateusz är att generera trace-filer efter varje fuzzning som beskriver hur en viss input uppnår en viss sökväg inom programmet.
I Wireshark har han hittat 35 st olika sårbarheter som åtgärdats. Han kompilerade Wireshark med ASAN och AsanCoveredge, och Wireshark var ett bra mål för att majoriteten av alla dissectors är skrivna i programspråket C.
Det andra programmet han har lagt mycket tid på att fuzza är Adobe Flash, där identifierade han bl.a. två nya filformat som Adobe Flash accepterade som inte var dokumenterade. Han hittade 7 nya sårbarheter genom att fuzza dessa odokumenterade format.
Föredraget handlar om att cyberskurkar blir bättre på OPSEC och lämnar mindre och mindre spår efter sig. Han ska försöka sig på att spåra skurkarna även om de byter smeknamn på internetforum.
Rekommenderar boken Activity based intelligence. Recorded Future har sparat på sig data under 4 år och crawlar många forum och darkweb-sidor. Stödjer 7 olika språk. De har nu identifierat 1,4 miljoner olika smeknamn på forum där 96.6% enbart är använda en gång.
Bygga kluster av aktivitet över längre tid på profiler som återfinnes på forum. Detta blir sedan heatmaps/swimlanes som kan jämföras mellan forumprofiler.
Det är möjligt att identifiera när en person på ett forum byter smeknamn genom att analysera aktivitet. Även går detta att analysera på Tor HiddenServices-forum. Detta är bara indikationer på att det kan vara samma person som är bakom ett smeknamn och bör kompletteras med mer information.
TheRealDeal Market är en marknadsplats för diverse illegala prylar såsom 0-days, droger och RAT:s.
Att ta sig förbi webb-brandväggar med hjälp av maskininlärning
Föreläsare: George Argyros och Ioannis Stais
En webbapplikationsbrandvägg fungerar genom att normalisera indata för att sedan matcha detta mot ett regelverk i korta drag. Regelverket kan vara i form av signaturer eller regular expressions. Om någon matchar så migreras sedan attacken på olika sätt genom att exempelvis helt enkelt blockera http-förfrågan.
Sedan går föreläsarna igenom några vanliga problem med denna typ av webb-brandväggar. Dessa problem kan vara felaktig normalisering av indata eller stöd för vissa protokoll som angriparen använder sig av. Ett enkelt sätt att ta sig förbi en webb-brandvägg kan vara att enbart använda single vs dubbel-quotes.
Genom att använda Angluins algoritm så kan en aktiv inlärningsalgoritm utvecklas. Denna algoritm kan sedan lära sig om eventuella problem som uppstår i WAF:en (web application firewall).
Denna metod kan även användas för att göra fingerprinting och således lista ut vilken typ av waf som används.
Föreläsare: Tal Be’ery och Itai Grady från Microsoft Research
Detta var helt klart dagens mest intressanta föredrag. Främst eftersom det först fokuserade på hur Microsoft lär sig av angriparen och sedan kan använda denna information till att detektera attacker samt bygga in skydd i Windows mot dessa. Även ett aktuellt ämne.
Angripare och försvarare har mycket gemensamt. Försöka ta sig in och sedan eskalera sina behörigheter genom att söka igenom nätverk och klienter. Från exempelvis att gå på ett phishing-mail till Microsoft domän-admin och exfiltration av känslig information.
När ett konto har identifierats så används någon av följande kommandon för att köra kod fjärrmässigt:
PsExec
Remote PowerShell WinRM
WMIexec
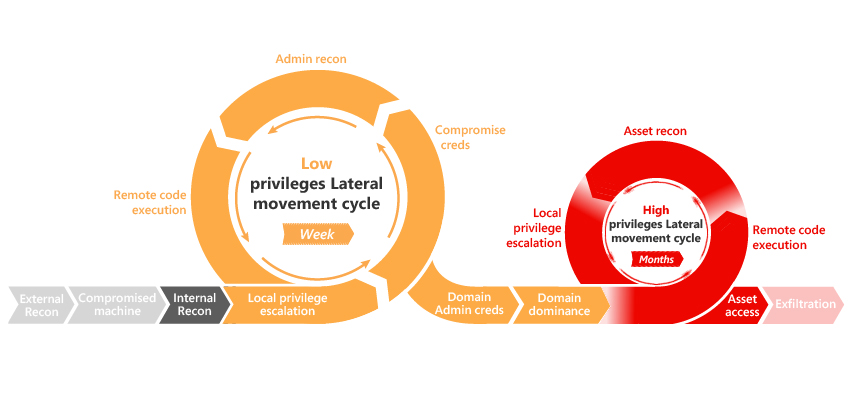
Följande bild illustrerar attack kill chain:
Vi behöver lära oss TTPs om våra angripare
Tools
Techniques
Procedures
Antagonisten är intresserad av användare som är domän-administratörer. Detta kan kontrolleras med SAMR över nätverket mot en domänkontrollant (DC).
För automatisera detta kan PowerSploit användas som ett PowerShell-script. Även kan verktyget BloodHound hjälpa till med att leta upp administratörer på nätverket. Nåväl, Microsoft Research har nu själva utvecklat ett nytt verktyg vid namn GoFetch som bygger en attackplan samt har inbyggt stöd för mimikatz.
Eftersom detta är ett problem för Microsoft så har de nu implementerat begränsningar i Windows 10. RestrictRemoteSAM är en ny registernyckel som kan sättas. Windows Server 2016 har också denna registernyckel.